
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
Tags
- java
- oracle
- 깃허브
- mybatis
- view
- 필기
- 쿠버네티스 기본 개념
- DB
- DDL
- github
- MVC 패턴
- docker 소개
- SQL
- DB 모델링
- 정보처리기사
- dql
- 프로그래밍 기초
- DB 개요
- VS Code
- java 기초
- 웹개발 기초
- 도커
- 마크다운
- 기초 선택자
- 쿠버네티스
- 데이터베이스
- docker
- 기본 API
- ORACLE 기초
- Flutter
Archives
- Today
- Total
핑구
01. DQL(SELECT) 본문
📅 2021.09.08 ~ 2021.09.09
주요 용어
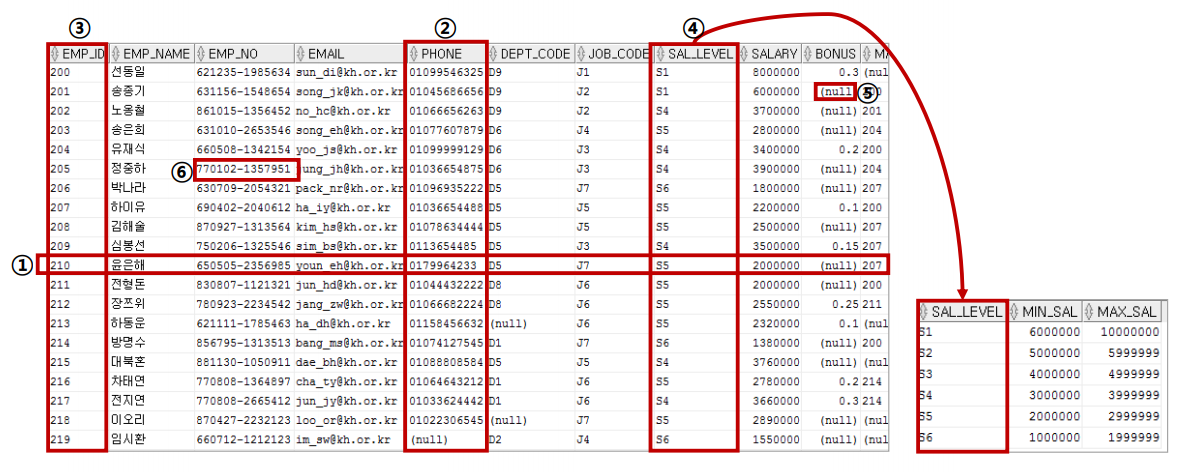
① 행, Row, 튜플
② 컬럼, 도메인
③ 기본키(Primary Key) : 행을 구분할 수 있는 유일한 인자로 하나의 행이 다른 행과 겹치지 않고 유일할 수 있도록 만들어 준다. 테이블 간에는 관계를 맺을 수 있는데, 이때 한 테이블의 프라이머리 키를 다른 테이블에 일반 속성으로 넣어 주면 관계를 맺을 수 있다.
④ 외래키(Foreign Key) : 원래 내 것이 아닌 외부에서 받아온 키를 의미한다.
⑤ Null : 안에 아무것도 들어있지 않은 부분을 의미한다.
⑥ 컬럼값, 속성값, 칸 하나하나의 값을 의미한다.
SQL
- 관계형 데이터베이스에서 데이터를 조회하거나 조작하기 위해 사용하는 표준 검색 언어로 원하는 데이터를 찾는 방법이나 절차를 기술하는 것이 아니라 조건을 기술하여 작성한다.
- 분류
- DQL(Data Query Language)
데이터 검색/조회에 사용된다.
명령어 : SELECT(데이터 검색) - DML(Data Manipulation Language)
데이터 조작에 사용된다.
명령어 : INSERT(데이터 삽입), UPDATE(데이터 수정), DELETE(데이터 삭제) - DDL(Data Definition Language)
데이터 정의에 사용된다.
명령어 : CREATE(객체 생성), DROP(객체 삭제), ALTER(객체 수정)
이때 객체란 테이블, 계정 등을 의미한다. - TCL(Transaction Control Language)
트랜젝션 제어에 사용된다. 트랜젝션 제어란 데이터를 조작하는 경우 데이터베이스 상에서 변화가 일어나는데, 그 변화에 대해 결정하는 것을 의미한다.
명령어 : COMMIT(변경 등에 대한 데이터베이스 확정), ROLLBACK(최근 커밋한 시점으로 데이터베이스 되돌리기)
- DQL(Data Query Language)
SELECT
- Result Set : 데이터를 조회한 결과로 SELECT 구문에 의해 반환된 행들의 집합을 의미한다. 검색한 결과가 없는 경우에도 Result Set은 생성되기 때문에 0개 이상의 행이 포함될 수 있다. 특정 기준에 의해 정렬 가능하다.
- 한 테이블/여러 테이블의 특정 컬럼, 행, 행/컬럼 등 원하는 것들을 조회 가능하다.
- 작성 방법
SELECT 컬럼명[, 컬럼명, ...]
FROM 테이블명
WHERE 조건식 - SELECT : 조회하고자 하는 컬럼명을 기술하며, 이때 컬럼명은 하나 이상일 수 있다. 여러 개의 컬럼을 조회하는 경우 컬럼은 쉼표로 구분한다. 마지막 컬럼 다음에는 쉼표를 사용하지 않는다. 모든 컬럼을 한꺼번에 조회 시 '*' 기호를 사용하여 조회 가능하며, 조회 결과는 기술한 컬럼명 순서대로 표시된다.
- FROM : 조회 대상 컬럼이 존재하는 테이블명을 기술한다.
- WHERE : SELECT와 FROM은 필수적으로 작성하여야 하나, WHERE은 필수적이지 않으며, 원하는 조건이 존재할 경우에만 작성하면 된다. 여러 개의 조건을 포함할 수 있으며, 각각의 제한 조건은 논리 연산자로 연결된다.
- 컬럼 값 안에서 연산이 가능하며, 연산을 하는 경우 Result Set에 해당 컬럼 명은 연산식으로 저장이 된다. 만약 연산을 할 때 null인 값이 존재한다면 해당 값의 결과는 null이 출력된다.
SELECT EMP_NAME, SALARY*12 -- 컬럼명 : SALARY*12 FROM EMPLOYEE;
위 경우처럼 해당 컬럼이 어떤 컬럼인지 구분하기 힘든 경우에는 컬럼에 별칭을 넣어 구분한다. 별칭을 넣는 방법은 아래와 같다.- 컬럼명 AS 별칭
- 컬럼명 "별칭"
- 컬럼명 AS "별칭"
- 컬럼명 별칭
- 오늘 날짜를 이용한 연산이 필요한 경우 SYSDATE를 사용하여 계산할 수 있으나, SYSDATE에는 시간까지 저장되어 있기 때문에 결과가 시간이 합쳐진 소수로 출력된다.
- Result Set에는 리터럴을 포함시킬 수 있다. 리터럴이란 문자 그대로의 데이터를 말하며, 테이블에 존재하지 않아도 Result Set에 추가가 가능하다.
SELECT EMP_ID, EMP_NAME, SALARY, '원' 단위 FROM EMPLOYEE;
SQL에서 ""은 별칭에 사용하기 때문에 문자(문자열)을 나타낼 때는 ''으로 묶어 나타낸다. - DISTINCT : 컬럼에 포함된 중복 값을 한 번씩만 표현하고자 할 경우 사용되며, 해당 값의 순서는 임의로 출력된다.
DISTINCT는 SELECT절에서 딱 한 번만 사용이 가능하며, 제일 앞에 사용하는 경우 뒤에 있는 컬럼에도 중복 제거가 적용된다. 단, 두 컬럼을 묶어 중복 제거가 적용되는 것이기 때문에 두 컬럼 모두와 같은 컬럼이 존재하는 경우에만 제거된다.SELECT DISTINCT JOB_CODE FROM EMPLOYEE;
또한 DISTINCT는 여러 개의 컬럼을 검색한 후 하나의 컬럼에만 적용할 수 없다. 그 이유는 다른 컬럼의 속성 값이 서로 다른 상태에서 하나의 컬럼에서만 중복 제거를 하는 경우 어떤 속성 값을 불러와야 하는지 알 수 없기 때문이다. - WHERE
- 비교 연산자
= : 같다
> : 크다
< : 작다
>= : 크거나 같다
<= : 작거나 같다
!=, ^=, <>: 같지 않다- LIKE: 특정 패턴을 만족시키는 경우가 있는지 조회한다. 패턴은 % 또는 _를 사용하여 검색하며, 각각의 용도는 다음과 같다.
- %: 0글자 이상일 경우 사용
'글자%' : 글자로 시작하는 값 ex. 글자, 글자뭐지 등
'%글자%' : 글자가 포함된 값 ex. 글자, 글자뭐지, 내글자 등
'%글자' : 글자로 끝나는 값 ex. 글자, 내글자 등
'글%자' : 글로 시작해서 자로 끝나는 값 ex. 글자, 글의남자 - _ : 딱 1글자일 때 사용
'_': 한 글자
'__': 두 글자
'___': 세 글자
'%', '_' 문자를 와일드 카드라고 한다.
LIKE 또한 NOT을 같이 사용하면 해당 패턴을 만족하지 않는 경우를 검색할 수 있다.
ESCAPE OPTION : 와일드 카드 문자와 실데이터가 동일한 경우에는 컴퓨터가 구분할 수 없기 때문에 예상한 데이터의 추출이 불가능하다. 따라서 이 경우에는 ESCAPE OPTION이 필요하다. ESCAPE OPTION은 아래와 같이 사용하며, 1 Byte의 특수문자를 사용하면 어떤 특수문자를 사용하든 상관없다.
SELECT EMP_ID, EMP_NAME, EMAIL FROM EMPLOYEE WHERE EMAIL LIKE '___ _%' ESCAPE ' '; - %: 0글자 이상일 경우 사용
- IS NULL/IS NOT NULL: 컬럼 값에 NULL 값이 들어있는지 안 들어있는지 판별해준다.
- IN: 목록에 일치하는 값이 있으면 TRUE를 반환하며, IN(컬럼값) 형태로 사용한다. OR로 연결되는 값인 경우 IN으로 묶어 사용할 수 있다.
- LIKE: 특정 패턴을 만족시키는 경우가 있는지 조회한다. 패턴은 % 또는 _를 사용하여 검색하며, 각각의 용도는 다음과 같다.
- 논리 연산자
AND : ~고, 동시에 (&&)
OR: 또는, 이거나 (||)
AND와 OR 중에서는 AND가 우선 순위가 더 높기 때문에 만약 동시에 여러 개를 사용하는 경우 소괄호를 사용하여 우선 순위를 확실하게 정해 주어야 한다.
BETWEEN AND : 하한값 이상, 상한값 이하인 경우에는 BETWEEN AND 사용이 가능하다.
SELECT EMP_ID, EMP_NAME, SALARY, DEPT_CODE, JOB_CODE FROM EMPLOYEE WHERE SALARY BETWEEN 3500000 AND 6000000;
BETWEEN AND의 반대 상황은 OR를 사용하여 표현할 수도 있으나, BETWEEN AND에 NOT를 붙여 표현도 가능하다.SELECT EMP_ID, EMP_NAME, SALARY, DEPT_CODE, JOB_CODE FROM EMPLOYEE --WHERE NOT SALARY BETWEEN 3500000 AND 6000000; --WHERE SALARY NOT BETWEEN 3500000 AND 6000000; -- 결과 반전 시 사용되며 NOT의 위치는 둘 다 가능하다 - 연결 연산자(||) : 데이터를 연결하여 출력해주며, 리터럴과도 연결이 가능하다.
- 비교 연산자
- ORDER BY : 정렬할 때 작성하는 구문으로 SELECT의 가장 마지막 부분에 작성하며, 실행 순서 또한 가장 마지막이다. 컬럼명/별칭/컬럼순번 중 하나로 정렬하며, 별칭을 인식하는 이유는 가장 마지막에 실행되기 때문이다. 이때 순번은 SELECT에 정의된 순번이다.
오름차순 : ASC(생략 가능)
내림차순 : DESC(생략 불가능)
정렬 시 NULL의 순서를 제어하기 위하여 NULL FIRST/NULL LAST를 사용한다. NULL LAST를 사용하지 않고 내림차순으로 정렬하는 경우 NULL이 제일 위에 정렬된다.
Table
- 열: 테이블의 정보를 나타내는 부분이다.
- DATA_TYPE : 데이터의 타입을 보여 준다.
NUMBER : 숫자형 데이터
DATE : 날짜형 데이터
CHAR : 문자를 받는 자료형(불변), 지정한 크기보다 적게 입력되는 경우 남은 공간에 공백 문자가 채워진다.
VARCHAR2 : 문자를 받는 자료형(가변), 지정한 크기보다 적게 입력되면 남는 공간은 입력된 크기에 맞게 줄어든다. - CHAR와 VARCHAR2 모두 지정한 크기를 초과하는 것은 불가능하다.
- NULLABLE: NULL이 들어갈 수 있는지에 대한 여부
- DATA_DEFAULT: 데이터의 기본 값
'JAVA 웹 개발 > 2. Oracle' 카테고리의 다른 글
| 05. 서브쿼리 (0) | 2022.06.08 |
|---|---|
| 04. JOIN (0) | 2022.06.08 |
| 03. GROUP BY HAVING (0) | 2022.06.08 |
| 02. 함수 (0) | 2022.06.08 |
| 00. Oracle Database 개요 (0) | 2022.05.16 |